Entering the field of explainable artificial intelligence (XAI) entails encountering different terms that the field is based on. Numerous concepts are mentioned in articles, talks and conferences and it is crucial for researchers to familiarize themselves with them. To mention some, there’s explainability, interpretability, understandability, comprehensibility, transparency, and intelligibility. But clear definitions and a consensus of the field on what these concepts differentiate from each other is missing. They all relate to the socio-technical relation between human and algorithmic model, but incapsulate different notions of activity and passivity in their degree of explanation, understanding and level of comprehension. This leads to confusion in the field of what concepts to use in guidelines, toolkits and discussions on AI ethics, where clarity is often difficult to archive, but all the more important. For example, explainability and interpretability are often interchangeably used. While Preece et al. (2018) understand interpretability as a concept focusing more on the human interpreting the model, Kaur et al. (2022) perceive interpretability starting from the perspective of the model to present their workings in an understandable manner, therefore defining explainability as the human-centered model, highlighting the ability of the human to understand (ibid.). It proves to be a challenge to navigate the field, weaving through the meaning of concepts and trying to make sense of them.
By showcasing their entangled and messy character, this blog post tries to find one way to deal with the multitude of concepts. This approach and the graph is inspired by an article by Arrieta et al. (2020), which gives an overview of the field of XAI and tries to differentiate its concepts by conducting a literature analysis and taking into account approximately 400 contributions.
When talking about the field of XAI, it seems sensible to start with the concept of explainability. Explainability can be defined as the ability of humans to make sense of the model’s workings by producing an explanation or rationalizing its output (Ehsan et al. 2021). This entails the human producing an explanation – either ante-hoc or post-hoc – to make sense of the model’s workings or trying to rationalize its output data in human-understandable terms. Interpretability then acts as the counterpart to explainability, approaching the production of an explanation from the model’s side. Interpretability describes the ability of a model to present their workings in a way that is understandable to humans. This model-centric perspective therefore deals with the model being able to be interpreted by the human. Interpretability can be viewed as a degree of intelligibility, which is the extent to which the model or its functions can be understood by the human. Intelligibility, or also understandability, describes the characteristic of a model that determines to what extent the human can understand the model’s function. Comprehensibility is another degree of intelligibility, and can be characterized as the ability of a model to depict its learned knowledge in a way that is understandable to humans. Therefore, comprehensibility is also a model-centric concept, but focuses on the workings of the model rather than the algorithm itself. Transparency can be seen as an ideal of interpretability that is not possible to reach within deep learning models. Transparency is the ability of a model to be understandable on its own to the human, making it another concept where the model acts as a starting point of analysis. It can be subdivided into simulatability, decomposability and algorithmic transparency, which display varying degrees of interpretability related to which parts of the model can be understood in what specific way.
The following graph can serve to better understand the relation between the concepts of explainability, interpretability, comprehensibility, transparency and intelligibility and how they affect the entanglement between user and model:
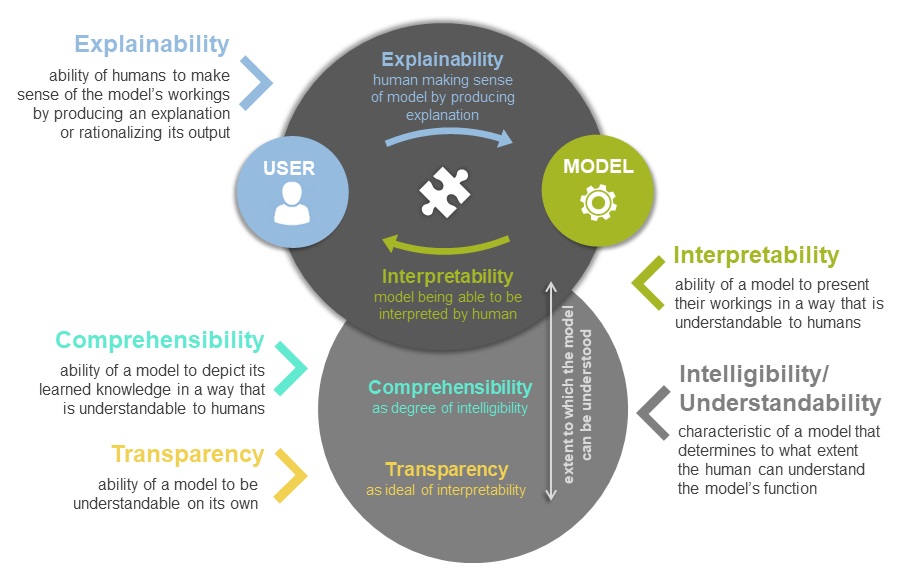
This is only one approach of making sense of these concepts, but no claim to accuracy and completeness. Other concepts have emerged as well, such as accountability, responsibility, or opacity, that are interrelated with these concepts discussed as well. Drawing on Louise Amoore’s (2020) work on Cloud Ethics, I propose that instead of only advocating for clear definitions, these messy concepts can also open up a space for discussion. Questioning the field’s contextual background and patterns of analysis can be fruitful in its own way. This is an invitation to discuss how we understand these messy concepts and examine in what way this relates to how we approach the field of XAI.
Sources:
Amoore, L. (2020). Cloud ethics: Algorithms and the attributes of ourselves and others. Duke University Press.
Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., Garcia, S., Gil-Lopez, S., Molina, D., Benjamins, R., Chatila, R., & Herrera, F. (2020). Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion, 58, 82–115. https://doi.org/10.1016/j.inffus.2019.12.012 
Ehsan, U., Liao, Q. V., Muller, M., Riedl, M. O., & Weisz, J. D. (2021). Expanding Explainability: Towards Social Transparency in AI systems. In Y. Kitamura, A. Quigley, K. Isbister, T. Igarashi, P. Bjørn, & S. Drucker (Eds.), CHI’21: Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems: making waves through strength: May 8-13, 2021, Online Virtual Conference (originally Yokohama, Japan) (pp. 1–19). Association for Computing Machinery. https://doi.org/10.1145/3411764.3445188
Kaur, H., Nori, H., Jenkins, S., Caruana, R., Wallach, H., & Wortman Vaughan, J. (2020). Interpreting Interpretability: Understanding Data Scientists’ Use of Interpretability Tools for Machine Learning. In R. Bernhaupt (Ed.), ACM Digital Library, Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (pp. 1–14). Association for Computing Machinery. https://doi.org/10.1145/3313831.3376219
Preece, A. (2018). Asking ‘Why’ in AI: Explainability of intelligent systems – perspectives and challenges. Intelligent Systems in Accounting, Finance and Management, 25(2), 63–72. https://doi.org/10.1002/isaf.1422


